Asthma Risk
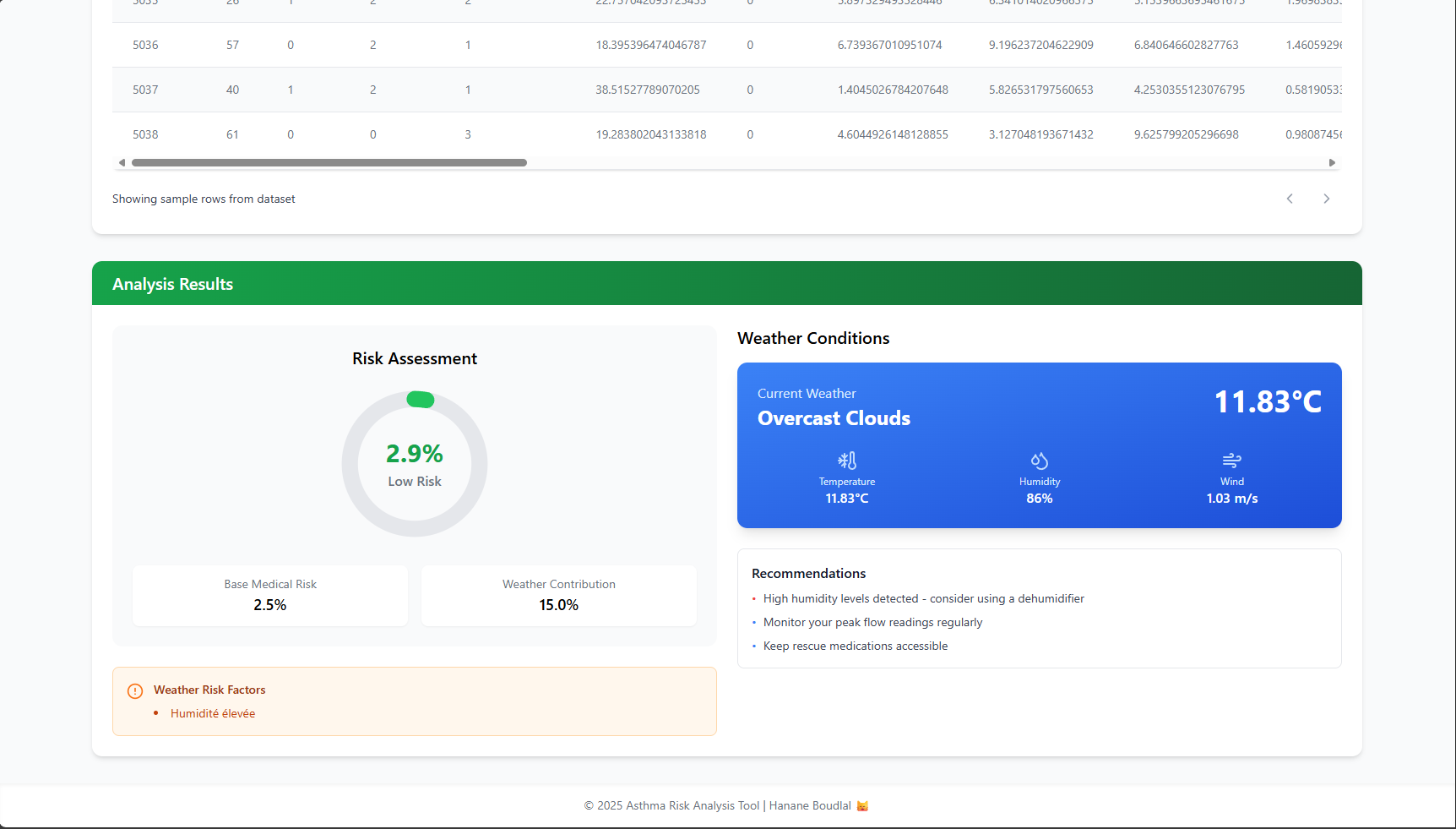
AI applicationDevelopment of an asthma risk prediction application combining a machine learning model (Random Forest) trained on clinical data with real-time weather data from the OpenWeatherMap API. Integration of a caching system, calculation of weather-related risk factors, and evaluation of the combined probability of an asthma attack.
Key Features
- ✓Machine Learning Integration: Trained a Random Forest model on clinical data to predict asthma risk.
- ✓Real-Time Weather Data: Fetched and integrated live meteorological data using the OpenWeatherMap API.
- ✓Combined Risk Evaluation: Merged clinical and environmental factors to compute the overall probability of an asthma attack.
- ✓Caching System: Implemented a cache mechanism to reduce redundant API calls and improve performance.
- ✓Risk Factor Computation: Analyzed specific weather indicators (e.g. humidity, temperature, air quality) to quantify their impact on asthma.
- ✓Modular Architecture: Designed the application with a clean separation between data collection, processing, prediction, and UI layers.
- ✓User Interface (optional): (If applicable) Developed a user-friendly interface for displaying risk levels and weather insights.
Technologies
Handling Missing Data (Heart Disease Dataset)
Data ScienceA data science project focused on analyzing and handling missing values in a medical dataset (heart disease). Various imputation and deletion techniques were applied and evaluated using classification models like Random Forest and XGBoost.
Key Features
- ✓Analyzed missing data using statistics and visual tools (missingno)
- ✓Applied multiple imputation strategies: mean, median, constant, KNN, , Forward Fill - Backward Fill - Linear Interpolation , linear regression(random forest).
- ✓Used deletion methods: Pairwise , Listewise , dropping entire column.
- ✓Trained and evaluated models to compare accuracy across methods.
Dataset
1K entrées
Technologies
Fake News Detection – Text Classification
Data ScienceDeveloped a binary classifier to detect fake news from real news using text data. The project included full preprocessing of text, feature engineering, and model comparison.
Key Features
- ✓Analyzed dataset and class distribution (Fake vs Real).
- ✓Cleaned and normalized text (stopword removal, stemming, lemmatization).
- ✓Extracted linguistic features (POS tagging: nouns, verbs, adjectives).
- ✓Represented text as vectors using CountVectorizer.
- ✓Trained multiple models: Logistic Regression, Decision Trees, Random Forest, Voting Classifier.
- ✓Applied cross-validation (KFold) for model robustness.
- ✓Evaluated each method using precision and recall metrics.
Dataset
6K entrées